WebAssemblyで自作言語用のGCを書く
前回の続きです。
概要
前回の記事ではWebAssemblyを出力するMLのサブセットコンパイラを作りました。しかし、WebAssemblyにはGabage Collection (GC) が未だに実装されていないため(2019/7/8時点)、メモリ管理は全て自分で行う必要があります。前回は超適当mallocで間に合わせていたのですが、今回はmalloc, freeを含むGCをWebAssembly(手書き)で作りました。
GCを含むMLコンパイラのソースコードはここで、GC本体はここです。
WebAssemblyの基礎知識
WebAssemblyはスタックマシンで実行される言語であり、各命令は引数をスタックのトップから取り出し結果をスタックのトップに積みます。トップ以外のスタックの中身を自由に見ることはできません1。また、スタックの他にもリニアメモリも持ち、i32.store, i32.loadといった命令でアクセスすることができます。リニアメモリは以下のような特徴を持ちます。
- アドレスは0から始まる
- アドレスは32bit
- 整数又は浮動小数点数をstore/loadできる
GCの実装
GCを書く前にまずmallocとfreeが必要です。今回はfree listでブロックを管理する簡単なものを書きました。各ブロックは下図のような構造になっていて、次のブロックのアドレス、ブロックサイズ、フラグ、確保したメモリを保持します。フラグにはfree listの終端かどうかの情報とブロックが使用中かどうかの情報が入っています。それぞれ4byteずつ使うのでmallocのためのヘッダだけで12byteも使います。贅沢ですね。
+-------------------------------------------------------+ | next block address | block size | flags | contents | | 4bytes | 4bytes | 4bytes | 4*n bytes | +-------------------------------------------------------+
mallocはfree listを先頭から走査して要求されたサイズ以上の空きブロックがあれば確保、最後まで走査して該当するブロックがなければ末尾に新たにブロックを作ります。freeは指定されたブロックの状態を空きブロックに変えるだけです。空きブロック同士を結合する処理はめんどくさいのでやっていません。
このmallocとfreeを使ってGCを作ります。『ガベージコレクション』によれば、GCには次の3種類があります。
- マーク・アンド・スイープ
- コピーGC
- 参照カウント
このうち、マーク・アンド・スイープとコピーGCは生きているオブジェクトを探索するのにルートセットが必要です。ルートセットは一般にレジスタ、スタック、グローバル変数から構成されます。ところが、WebAssemblyではスタックの中身を自由に見ることができないためルートセットが必要なGCは採用できません2。このため今回は参照カウント方式でGCを実装しました。
gc_malloc を呼び出すとmallocが指定されたサイズ+GCのヘッダサイズ分のメモリをリニアメモリ上に確保し、GCの管理情報を書き込んだ上でそのアドレスを返します。GCの管理領域は下図のようになっていて、確保したメモリのサイズ、参照カウントの値、フラグ、オブジェクトのためのメモリ領域から構成されています。フラグには参照カウント時に行う深さ優先探索用のビットと格納しているオブジェクトが値(整数値又は浮動小数点数)か否かの情報が含まれます。
+----------------------------------------------------+ | memory size | reference count | flags | contents | | 4bytes | 4bytes | 4bytes | 4*n bytes | +----------------------------------------------------+
これがmallocのcontentsの中に入っているので実際にはこのようになります。
+---------------+------------+--------+--------------------------------------------------------+ | next malloc | malloc | malloc | malloc contents | | block address | block size | flags | +----------------------------------------------------+ | | 4bytes | 4bytes | 4bytes | | memory size | reference count | flags | contents | | | | | | | 4bytes | 4bytes | 4bytes | 4*n bytes | | | | | | +----------------------------------------------------+ | +---------------+------------+--------+--------------------------------------------------------+
参照カウントはコンパイラが変数のスコープに応じてオブジェクトの参照カウントを増減させるコード(gc_increase_rc, gc_decrease_rc)を挿入することで操作します。基本的にオブジェクトの作成時に参照カウントが1増加し、そのオブジェクトを指す変数のスコープが終了したところで参照カウントが1減らします。参照カウントが0になるとそのオブジェクトは解放され、またそのオブジェクトが保持していたアドレスが指すオブジェクトの参照カウントを1減らします。この操作は再帰的に行われます。ただし、解放されたオブジェクトが値だった場合はこの再帰的な操作は行われません。
↓gc_increase_rc, gc_decrease_rcはこんな感じで挿入される
(i32.const 1) (i32.store))) (; let fun_fib_0 end ;) (call $gc_increase_rc) (get_local $val_b_6) (call $gc_decrease_rc) (drop) (get_local $val_a_5) (call $gc_decrease_rc) (drop)
基本的に参照カウントの操作は変数のスコープと連動させればよいのですが、関数終了時には特殊な処理が必要になります。関数内のローカル変数が指すオブジェクトは関数の終端で解放されますが、関数の戻り値が開放されるオブジェクトを含む場合、すでに解放されたオブジェクトが関数の戻り値に含まれることになります。このようなバグを防ぐためには、関数内のローカル変数を開放する処理を行う前に戻り値オブジェクトの参照カウントをインクリメントしておく必要があります。
その他にも配列の要素を書き換えるときは前のオブジェクトの参照カウントを減らしてから、新しく代入するオブジェクトの参照カウントをインクリメントする必要があるなど、細かいところでいろいろハマりました。
結果
フィボナッチ数列を第10項まで計算するプログラムでプログラム終了時のメモリ使用量をGC有りの場合と無しの場合で結果を比較してみると、以下のようになりました。使用メモリの4分の3ぐらいを解放できているのでそれなりに(僕が)満足できる結果です。
| - | メモリ使用量 |
|---|---|
| GCなし | 22868byte |
| GCあり | 4660byte |
let rec fib n = if n < 3 then 1 else let a = fib (n - 1) in let b = fib (n - 2) in a + b in let rec print x = if 10 < x then 1 else let a = fib x in print_i32 a; print (x+1) in print 0
参考リンク
- WebAssemblyでGCを実装する
GCの管理領域の設計はほとんどこの記事のものをそのまま使っています。 - WebAssemblyでGC
bitmap式のMark and SweepのGCを書く話。
余談
ONNXファイルから不要な枝を削ってMNISTの推論を高速化してみる
この記事の中のソースコードは全てhttps://github.com/akawashiro/sonnxにあります。
概要
- ニューラルネットワークから要らなそうな枝を80%削除しても精度が変わらなかった
- ONNXの中身をいじるのが大変だった
- onnxruntimeには勝てなかった
背景
機械学習の学習済みモデルを小さなデバイスで動かす、というのが最近流行っているそうです。機械学習では、学習には大きな計算コストがかかりますが、推論はそれほど大きな計算コストがかかりません。このため、学習だけを別のコンピュータで行っておいて、実際の推論は小さなデバイスで行うということが可能です。
ただし、推論だけでもそれなりに計算資源が必要です。そこで、学習済みのモデルの高速化が重要になります。Raspberry Piに搭載されているGPUを使うIdeinとか有名です。
僕も学習済みモデルの推論を高速化できそうな方法を思いついたので実験してみました。
アイデア
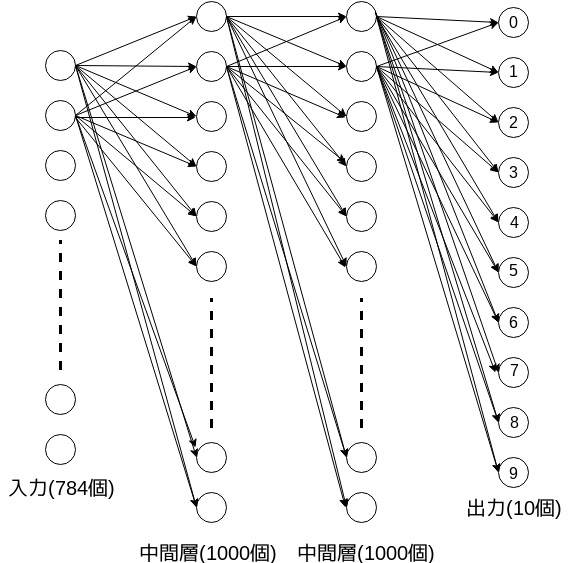
今回はMNISTを分類する学習済みモデルを高速化します。今回使用するモデルは次の図のようなものです。画像は28*28(=784)pxなので入力は784個、出力は各数字の確率なので10個あり、中間層が2つ挟まっています。各層間は全結合しており、活性化関数としてReluを使います。
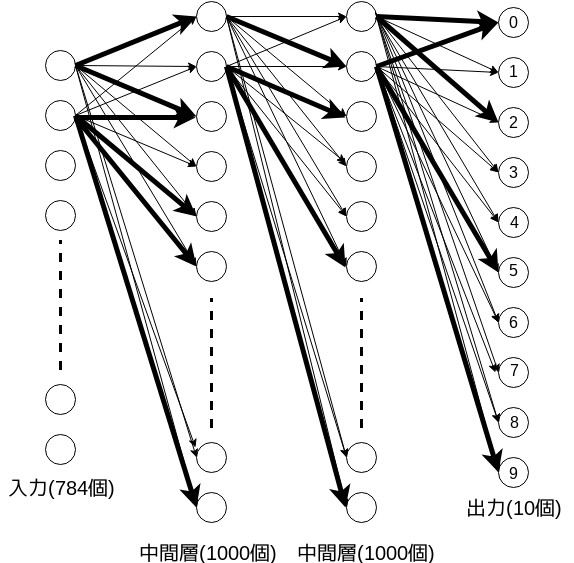
このモデルを教師データを使って学習すると、枝の重みが変わってこんな感じになります。
僕のアイデアは学習後のネットワークから重みの小さい枝を取り去ってもちゃんと動くんじゃないか、というものです。重みの小さい枝を取り去るとこんな感じになります。
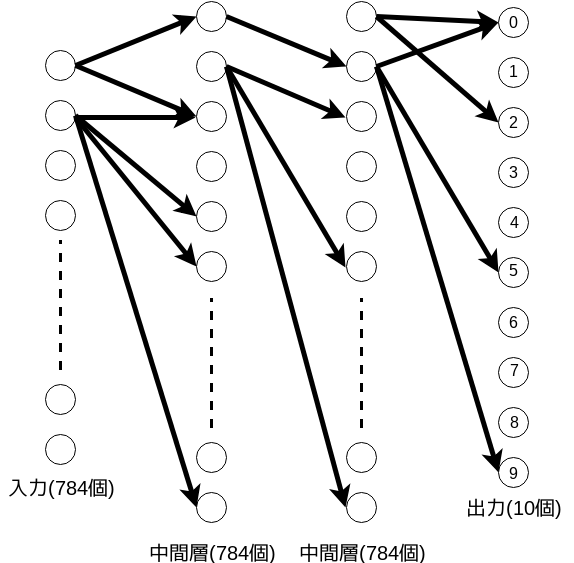
枝の本数が少なくなれば、推論を高速化できそうな気がします。
アイデアの裏付け
実際に学習後のモデルで赤丸で囲った部分の重みの分布を確認します。
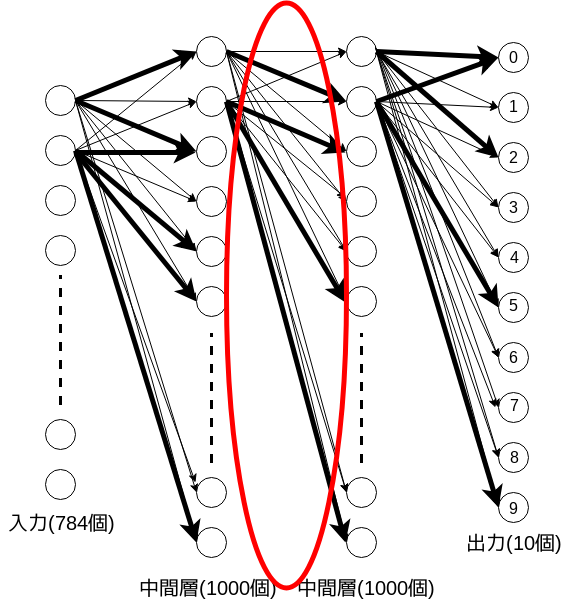
分布はこのようになっています。
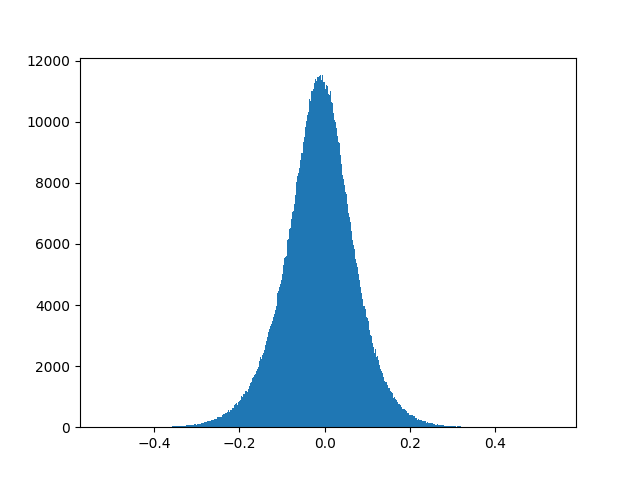
重みが0の部分が非常に多いです。まず、学習済みモデルから重みが0の枝を削除しても推論結果に影響しないはずです。また、グラフが左右対称になっているので、絶対値の小さい順に削除していけば、各パーセプトロンへの入力はそれほど変化しない気がします。
手法
やることは非常に単純です。ニューラルネットワーク中の各層間枝の重みの統計を取り、重み上位何%かを残して残りを削除します。つまり、何らかの方法で学習済みのモデルから枝の重みのデータを取り出し、枝をカットし、さらに加工後のモデルのデータを使って推論できるようにします。
幸い今はONNXという良いものがあります。ONNXとは学習済みモデルのデータを出力する形式の一つで、多くのフレームワークが対応しています。
今回はChainerで書いたモデルからONNXデータを出力し、そのデータを加工することにしました。また加工後のデータはC++で書いた俺俺ONNXランタイムに実行してもらうことにしました。
纏めると、
1. Chainerでニューラルネットワークを書いて学習する
2. 学習済みのニューラルネットワークからONNXデータを出力する
3. ONNXデータを俺俺ONNXランタイムに読み込んで加工、実行する
となります。一つづつ何をやるのかを説明します。
1. Chainerでニューラルネットワークを書いて学習する
2. 学習済みのニューラルネットワークからONNXデータを出力する
1と2は簡単です。onnx-chainerを使えばすぐにできます。
python3 learn_mnist.py
でmnist.onnxというファイルができます。
3. ONNXデータを俺俺ONNXランタイムに読み込んで加工、実行する
ここが大変でした。ディープラーニングフレームワークからのONNXモデルの出力は多くの人が試しているのですが、出力したONNXモデルをチューニングしようとする人はほとんどいないようです。
3.1 ONNXデータを解析する
とりあえずnetronというONNXの可視化ツールでmnist.onnxを可視化してみました。
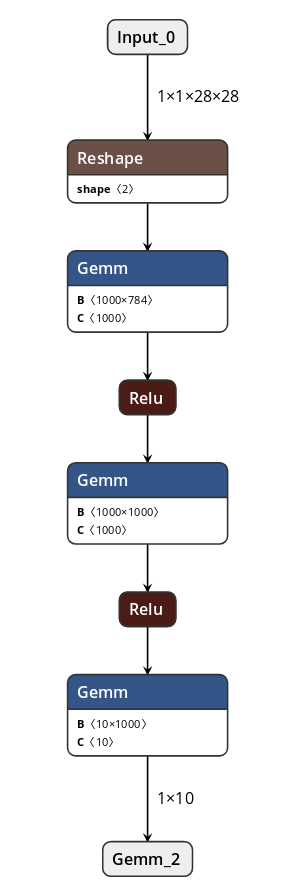
GemmはGeneral matrix multiplyの略です。各Gemmノードは行列BとベクトルCを持ち、ベクトルxを入力としてBx+Cを出力します。Reluは活性化関数です。
Reluはmax(0,x)で定義されている関数のでONNXから抽出する必要は無く、各Gemmノードの行列BとベクトルCの情報だけをを抽出できれば良いです。
今回は各GemmノードのBとCをテキストファイルとして抽出します。
> python3 analyze_mnist_onnx.py
は次のファイルを出力します。
*************_matrix.txt
mnist.onnxの全てのGemmノードのB行列とC行列*************_matrix.png
各行列の中の重みの分布mnist.onnx.json
ONNXファイルをJSONに変換したものmnist_train.txtmnist_test.txt
MNISTをC++から読み込みやすくするためにテキストファイルに変換したもの
各*************_matrix.txtがどのGemmノードに対応するのかはmnist.onnx.jsonを睨むとわかります(←ここ超不親切)。
3.2 抽出したデータを加工、実行する
g++ -O3 -mtune=native -march=native -mfpmath=both sonnx.cpp && ./a.out
で出力した重みのデータを読み込み、推論を実行します。sonnx.cppは簡単なONNXランタイムになっており、mnist.onnxから抽出した行列のデータとMNISTの画像データのテキストファイルから推論を行います。デフォルトではmnist_test.txtの10000枚について推論を行います。
出力はこのようになります。
accuracy, time 0.9817000031, 15.93887043 compress_ratio, accuracy, time 0, 0.9817000031, 36.66616821 0.05, 0.9817000031, 34.61940384 0.1, 0.9818000197, 32.64707184 0.15, 0.9818000197, 30.78090286 0.2, 0.9817000031, 29.01914406 ..........................
2行目は読み込んだデータを加工せずで隣接行列表現で保持したときの推論の精度と計算時間、4行目以降は読み込んだデータを加工したときの推論の圧縮率(compress_ratio)、精度と計算時間です。圧縮率が0のときは全く加工しないのと同じ、圧縮率が0.3のときは枝の重みの絶対値が小さい30%を削除したときの結果です。圧縮率が1になると全ての枝が削除されます。
データを加工して枝を削除するとき、sonnx.cppでは行列データを非零成分のインデックスとその値の組の配列として保持しています。これは枝を削除したときに保持するデータ量が減らし、高速に計算するためです。
結果
圧縮率を変化させたときの精度と計算時間のグラフです。圧縮率を0.8まで上げても推論の精度が変わっていません。これは学習済みモデル中の8割の枝を削除しても、推論精度が保てるということです。驚きですね!
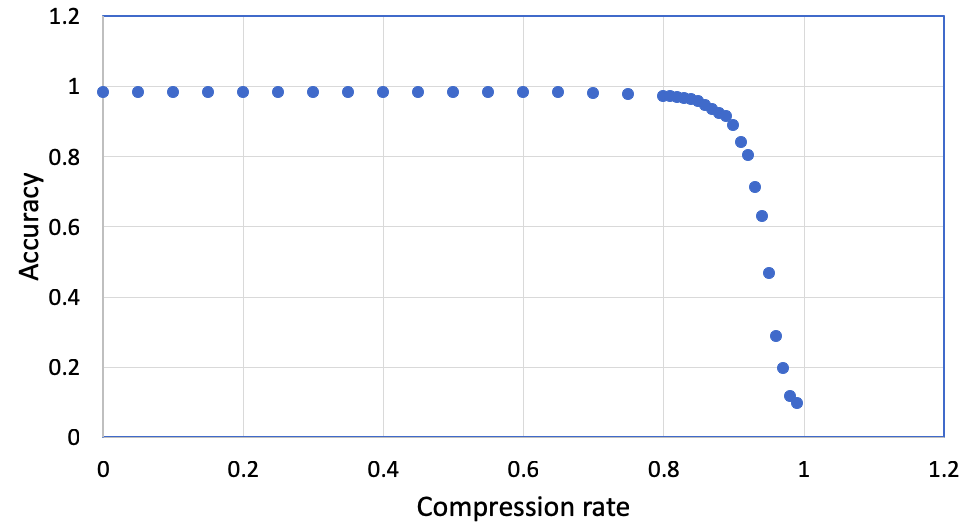
一方、計算時間はほぼ枝の数に反比例しています。これは予想通りでした。
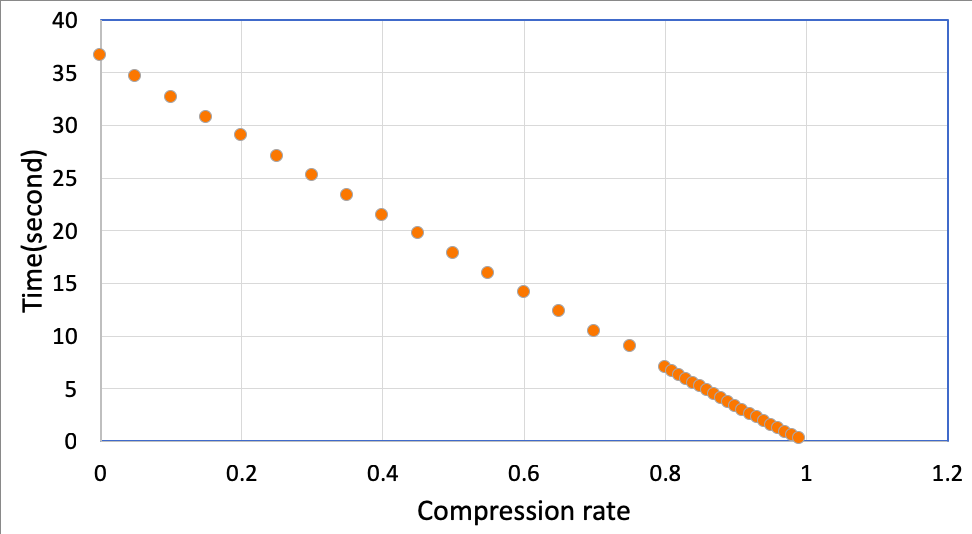
表にしてみます。推論精度を1%犠牲にするだけで2倍も高速化できています。やったね!
| 圧縮率 | 推論精度 | 計算時間(秒) |
|---|---|---|
| 0 | 0.981 | 15.9 |
| 0.8 | 0.971 | 7.04 |
※ 圧縮率0のときの値は重みのデータを隣接行列表現で保持したときのものです。
おまけ
最後にonnxruntimeで元の学習済みモデルを実行したときの時間を計ってみます。
> python3 analyze_mnist_onnx.py Accuracy rate = 0.9817 , time = 3.285153865814209
え、3秒?? 普通に考えると16秒ぐらいになるはずです。なぜこんなに速いんだ...
理由は色々あると思いますが、僕が思いつくのは以下の2つです。
- AVXなどのSIMD拡張命令を使っている
(僕もAVXを使おうとしましたが、scatter命令が僕のPCで使えないので諦めました。) - CPUのキャッシュに乗るようなプログラムになっている
関連記事・研究
- 深層学習のモデル圧縮・高速化に関する論文80本ノック
学習済みのモデルを圧縮する論文がまとめられています。このブログ記事の内容はリンク先の「スパースなモデル」の章に該当します。 - モデルアーキテクチャ観点からのDeep Neural Network高速化
DNNの高速化に関するスライドです。Pruningの章がこのブログ記事に該当します。 - Reducing the Model Order of Deep Neural Networks Using Information Theory
上のリンク中の論文で特にこの記事に近いものです。このブログ記事でやっているのは、この論文のmagnitude-based pruningです。 - Deep Compression: Compressing Deep Neural Networks with Pruning, Trained Quantization and Huffman Coding
CPUでの実行速度もオリジナルのモデルより速くなってるっぽくてすごい。何をどう実装したのか知りたい。 - keras-surgeon
kerasのモデルをpruningするためのソフトウェア。
まとめ
- ONNXランタイムを自作したらナイーブな実装の二倍の速度で推論ができた
onnxruntimeには勝てなかった
高階関数を基本的な関数の合成で作った関数でQuickCheckする
高階関数をQuickCheckでテストしてみる
QuickCheckを知っていますか?
QuickCheckと言うのはHaskellのデータ駆動型のテスト用ライブラリで
テストしたい関数を指定するとその引数に合わせて適当なテストデータを生成してくれます。
では高階関数(関数を引数に取る関数)をQuickCheckでテストすると
どんなテストデータ(関数)を生成してくれるのでしょうか。
ちょっと確認してみましょう。
-- QCTest.hs import Test.QuickCheck import Test.QuickCheck.Function prop :: Fun Integer Integer -> Bool prop f = apply f 10 == apply f 20 main = quickCheck prop
% stack runghc QCTest.hs
*** Failed! Falsifiable (after 2 tests and 12 shrinks):
{20->0, _->1}
...なんだこの関数は?
入力と出力の組が列挙されてるだけやんけ。
僕の思ってる関数と違うんですが。
map (+2)とかtailとかそういうやつを生成してほしいなぁ。
まともなテスト用関数を生成する
QuickCheckのテストデータが気に入らないので、まともな(主観)テストデータを生成してみました。
今回生成するテストデータは[Int] -> [Int]の関数に限定します。
そもそも関数を生成するってどうやればいいんでしょうか?
QuickCheckのように入力と出力の対を列挙するのは筋が悪い気がします。
mapや(+)、tailといった基本的な関数を合成して関数を生成したいのです。
我々がプログラミングするときってそうやりますよね。
入力と出力の組を列挙する人はあんまりいないと思います。
[Int] -> [Int]型の関数を列挙してみます。
tail reverse map (* 10) map (+ 10)
tailやreverseはそもそも[Int] -> [Int] 型です。
mapは(Int -> Int) -> [Int] -> [Int] 型なので
(+ 10) :: Int -> Intを渡すと[Int] -> [Int]型になります。
こんな風にどの関数(例 map)にどの関数(例 (+ 10))を適応すれば
どんな型(例 [Int] -> [Int])になるかを規則として書き出します。
型付け規則っぽく書くとこんな感じです。

ちょっとわかりにくいかも知れません。
[Int] -> [Int]型の関数を2つ作ってみました。

左はmap (+ 10)のような関数、右はmap (+ 10 (* 5))のような関数を表しています。
一番下の型にある関数の規則を持ってきて、上に必要な型を書いて
さらにその必要な型をもつ関数の規則を持ってきて...という感じです。
とりあえずこの規則を使って関数を生成できるようになりました。
[Int] -> [Int]型の関数を生成した例がこちらです。
% stack exec qcfun-exe > Test datum are following. > ["tail","reverse","(map (* 75))","tail","reverse"] ...
今見せた例はこのようなデータ型で表現されています。
data QProg = QMap1 QProg | QMap2 QProg QProg | QTail1 QProg | QTail | QRev | QMult QProg | QAdd QProg | QRand Int deriving (Eq) instance Show QProg where show (QMap1 p) = "(map " ++ show p ++ ")" show (QMap2 p1 p2) = "(map " ++ show p1 ++ " " ++ show p2 ++ ")" show (QTail1 p) = "(tail " ++ show p ++ ")" show (QTail) = "tail" show QRev = "reverse" show (QMult p) = "(* " ++ show p ++ ")" show (QAdd p) = "(* " ++ show p ++ ")" show (QRand i) = show i
QProg型がプログラム(関数)を表す型です。
このQProg型に対して適当なShowインスタンスを定義してあげると関数っぽく見えるようになります。
作ったテストデータ用の関数で高階関数をテストする
次に作った関数を使って高階関数をテストしてみましょう。
今回テストする対象のプログラムはこれです。
func f = reverse . f prop f = (func f [1,2,3]) == [1,2,3]
関数fを引数に取る簡単な高階関数funcの性質をテストします。
しかし作ったテストデータ用の関数はすべてQProg型です。
つまりQProg型をなんとかして[Int] -> [Int]型に変換したうえで
テストしたい高階関数に適用する必要があります。
今回はTemplate Haskellを使ってQProg型を[Int]->[Int]型のHaskellの関数に変換しました。
Template Haskellというのはプログラムの中でプログラムを作るためのツールです。
Lensなんかで使われています。
動作例がこちらです。
% stack exec qcfun-exe ... Test results are following. [(False,"tail"),(True,"reverse"),(False,"(map (* 75))"),(False,"tail"),(True,"reverse")]
テストデータは先頭から順に["tail","reverse","(map (* 75))","tail","reverse"]だったので正常に動いているようです。
まとめ
高階関数をまともな(主観)関数でテストできるようにしました。
しかし技術的な制約のためテストデータをコンパイル時に生成するので
テストデータを完全にランダムに生成することはできませんでした。
参考
http://haskell.g.hatena.ne.jp/mr_konn/20111218/1324220725
付録
githubへのリンクです
https://github.com/akawashiro/qcfun
以下のコマンドで実行できます。
git clone https://github.com/akawashiro/qcfun.git stack build stack exec qcfun-exe
WebAssemblyを出力するMinCamlコンパイラを実装しました
概要
WebAssemblyを出力するMinCamlコンパイラml2wasmをフルスクラッチで実装しました。
github.com
マンデルブロ集合を計算するこんな↓感じのMinCamlのソースコードが

こんな↓感じのWebAssemblyに変換されて

実行して、適切にプロットするとこんな↓感じになります。

導入
WebAssemblyとは
WebAssemblyとはブラウザで実行可能な低級プログラミング言語であり、仮想的なスタックマシン上で動作します。 また、JavaScriptに比べて構文解析が容易であり高速に動作します。 WebAssemblyは最近のほとんどのブラウザで動かすことができます。*1
;; WebAssembly のテキスト表現の例 (module (func (export "add") (result i32) (i32.add (i32.const 1) (i32.const 3))))
MinCamlとは
MinCamlとは東北大学の住井先生*2が設計したプログラミング言語MLのサブセットです。 言語仕様が小さく、処理系を制作するのが比較的容易なのが特徴です。 住井先生は未踏事業としてMinCamlのコンパイラも制作されています。 このコンパイラは読みやすくドキュメントもしっかりしているので、コンパイラを作ってみたい人には非常にオススメです。 ml2wasmの開発でもこのコンパイラを大いに参考にしました。
(* MinCaml の例 *) let rec add = 1 + 3 in add
コンパイラの作成
今回はMinCamlのソースコードをWebAssemblyのテキスト表現に変換するコンパイラml2wasmを作成しました。 基本的にml2wasmはオリジナルのMinCamlコンパイラと同じ構造ですが、WebAssemblyがスタックマシンであることを利用していくつかの変換の工程が省略されています。
ml2wasmの実装の詳細
ml2wasmでは次の5段階の工程でMinCamlをWebAssemblyに変換します。
特に説明のない部分はオリジナルのMinCamlコンパイラと同じです。 今回はHaskellで実装しましたが、もともとの実装言語がOCamlでHaskellとそれほど変わらないので、その点は苦労しませんでした。 以下、WebAssembly特有のコンパイラ実装事情をいくつか説明します。
オリジナルのMinCamlコンパイラには3と4の間にK正規化、4と5の間にレジスタ割当という処理がありましたが、ml2wasmではこれら2つの処理を省略しています。 K正規化はWebAssemblyでは命令のオペランドとしてスタックの先頭の値を使い、オペランドをレジスタに格納する必要がないため、 レジスタ割当はWebAssemblyにはレジスタが存在しないため、それぞれ省略できました。
逆に、WebAssembly特有の難しい工程としてはコード生成があります。
通常、関数型言語のコンパイラではプログラムをクロージャ変換し、関数から自由変数を削除します。
その後コード生成の工程で関数呼び出しは間接ジャンプ(MIPSならjr命令)に変換されます。
この間接ジャンプをWebAssemblyではcall_indirect命令で実現します。
;; call_indirect命令はこんな感じで呼び出される。 ... (i32.load) (call_indirect (param f32) (param f32) (param i32) (result i32))))) ... ;; (param f32) (param f32) (param i32) (result i32) ← 型が必要
ここで問題になるのがcall_indirect命令が呼び出す関数の型をオペランドとして要求する点です。
これはクロージャ変換後の中間言語に型情報を残しておく必要があることを意味します。
コンパイラを書き始めたときにはこのことに気づかなかったので、あとから型情報を追加するのに苦労しました。
他には公式のリファレンスがどこにあるのかイマイチわからない問題もあります。 結局これを使ったのですが、 URLに公式感がなく最後までこのリファレンスが公式のものなのかはわからずじまいでした。
結果
マンデルブロ集合を出力するプログラムをコンパイルできるようになりました! やったね!
マンデルブロ集合を出力するMinCamlのソースコード
mandelbrot.ml · GitHub
コンパイル結果
mandelbrot.wast · GitHub
ちなみにマンデルブロ集合っていうのはこんな↓やつです。

今回作ったコンパイラでコンパイルし実行した結果(を適切にプロットしたもの)は↓
まあ大体あってますね。点の数が以上に少ないのは大量の点をプロットしようとするとすぐにメモリ不足に陥るからです。
今後の課題
ml2wasmで出力したWebAssemblyコードはすぐにメモリ不足に陥ります。 理由は単純でGCがないからです。 WebAssemblyでGCを実装する試みとしては κeenさんのWebAssemblyでGC | κeenのHappy Hacκing Blog がありますが、今回はめんどくさいのでメモリは確保しっぱなしです。
そのうちWebAssemblyにデフォルトでGCが入るとかいう噂も聞くので、そのときにGCを入れればいいやと思っています。
参考リンク
- WebAssembly
WebAssemblyの公式ページ - 速攻MinCamlコンパイラ概説
MinCaml - WebAssemblyでGC | κeenのHappy Hacκing Blog
κeenさんによるWebAssemblyでのGCの実装 - wasm-reference-manual/WebAssembly.md at master · sunfishcode/wasm-reference-manual · GitHub
WebAssemblyの仕様書(?)。多分公式ではないが一番役にたった
*1:https://github.com/WebAssembly/wabtを使うとコマンドラインでWebAssemblyを試せます。
*2:設計した当時はペンシルバニア大学に所属していたようです 美しい日本のMLコンパイラ – 未踏iPedia -まだ誰も踏み入れたことのない世界へ-
ネットワークデバイスドライバを一からビルドしてインストールした
概要
新し目のコンピュータにDebianを入れたら、ネットワークデバイスドライバが入ってなくて結構大変だった。
経緯
最近、自分の使っていたコンピュータ(6年前くらいのデスクトップ)に限界を感じ始めたので、日本橋で新しいものを買ってくることにした。購入に当たっては、換装が難しいCPUをCorei7 8700kに決定し、フィーリングで選ぶことにした。日本橋を端から端まで歩き回って、結局LM-iH700XD1-EX4を買った。

Windows10をDebian streachで上書きして起動すると、ネットワークドライバが入ってないことがわかった。マザーボードが新しすぎるのでドライバがDebianに取り込まれていないのだろう。こういう場合は自前でドライバをビルドする必要がある。
NIC(Network Interface Card)の型番を調べる
まず、NICの型番を調べる。商品のスペックを確認したが、「LAN:10/100/1000BASE-T LAN(オンボード)」としか書いていない。マザーボードの方には「マザーボード:Intel B360 Micro ATX LGA1151」と書いてあった。オンボードのNICなのだから、たぶん「Intel B360」のほうが関係しているのだろうと考えられる。ここから「Intel B360 network driver」などで検索して一時間ほど頑張ったが、なんの成果も得られなかった。
% lspci (省略) 00:1f.6 Ethernet controller: Intel Corporation Device 15bc (rev 10)
なるほど、「Intel Corporation Device 15bc linux driver」で検索すれば良さそうである。検索すると、Linux Kernel Driver DataBaseがトップに出てきた。「15bc 」でページ検索すると
vendor: 8086 ("Intel Corporation"), device: 15bc ("Ethernet Connection (7) I219-V")
が出てくる。「I219-V linux driver」で検索してみると「e1000e」の最新のドライバを入れればいいらしい?
そこで、もうどこで見たのか忘れたけど Intel Ethernet Drivers and Utilities の最新版をインストールすればいいらしい。(検索しすぎて記憶がないorz)
makeを入れる
というわけでe1000e-3.4.2.1.tar.gzをビルドする。 ネットワークに繋がらないので別のパソコンでファイルをダウンロードしてUSBメモリでコピーした。
展開して、make installすると...makeコマンドが入ってないと言われた。
Debianのインストール元のlive USBをマウント後、apt install build-essentialで入れた。
最初から入れといてほしい...
デバイスドライバをビルドする
e1000e-3.4.2.1.tar.gzを展開して、make installするとカーネルのヘッダファイルが足りないと言われた。
% uname -a Linux gley 4.9.0-8-amd64 #1 SMP Debian 4.9.110-3+deb9u4 (2018-08-21) x86_64 GNU/Linux
4.9.0-8-amd64のヘッダファイルが必要なようだ。別のパソコンで該当のdebファイルを落としてきてdpkg -iで入れる。ちなみにcommonとamd64の両方が必要だった。
その後、再度make install。
再起動するとネットワークに繋がっていた。
ネットワークデバイスドライバをインストールできた〜〜〜〜嬉しい〜〜〜〜
— a_kawashiro (@a_kawashiro) September 27, 2018
まとめ
新し目のパソコンでLinuxを動かすのは大変。 ただドライバをビルドしてインストールする作業は初めてで勉強になった。 もうやりたくない。
ちなみにオーディオデバイスドライバが入っていないので音は出ない。 そのうち頑張る。
このマザーボード新しすぎて音も出せないwww
— a_kawashiro (@a_kawashiro) September 27, 2018
プログラミング言語Egisonの型システムを設計するインターンをした
概要
2018年3月11日から4月14日まで楽天技術研究所でEgisonの型システムの設計 & 型検査器を書くインターンをしていた。 もうインターンから半年も経ってしまったが、何も書かないよりはましというわけでブログ記事を書くことにした。
実装した型検査器はここにある。 まだまだ不完全ではあるが、一応動くのでよかったら試してみてほしい。
Egisonとは
Egisonとは江木さんという方が開発しているLisp likeなプログラミング言語で、非常に強力なパターンマッチ機構を持つ言語である。 江木さんは2007年からほぼ一人でEgisonを開発し続けており、その歴史はここで見ることができる。 最近ではパターンマッチ機構を活かして、数式処理システムの制作に使われている(江木さんがつかっている)。
インターンが始まるまで
Twitterをぼんやり眺めていたら「Haskellで言語実装するバイトがある!」ということで即応募した。 DMを送ったらSkypeで面接することになって、そのまま採用してもらった。 普段は京都に住んでいるので、東京に行かずに済んだのはすごく助かった。楽天技術研究所では,現代数学を簡潔に記述するためのプログラミング言語EgisonをHaskellで開発する方(アルバイトやインターンなど)を募集しています.
— Egison (@Egison_Lang) 2017年11月13日
Haskellで言語実装することに興味ある方は,ぜひDMください!
採用が決まった後は、Egisonが微分幾何の記述に使われるということなので局面と曲線の微分幾何を読んでいた。 研究室でPPL2018に行ったら隣の席に江木さんがいて、そのとき初めて江木さんに会った。
インターン初週
インターン初日、東京で疲れてしまったのか、高熱と吐き気がして会社を休んだ。 社会人失格かと思ったが、次の日出社したら「大丈夫ですか」と気遣ってくれて嬉しかった。 後でTwitterを見た感じ、東京で風邪が流行っていたらしい。
インターン初週はEgisonの実装を読むことが主な業務だった。 Egisonは巨大な構文木インタープリタとして実装されており、相次ぐ機能の拡張によってエライことになっていることが分かった。
インターン2週目
江木さんがEgisonに型検査を入れたいというので、Egisonのサブセットを抽出、定式化をして、そのサブセットに対して型システムを設計しようという話になった。
Egisonにはmatcherやprimitive patternなどの通常の言語には無い構文要素があり、ちょっと大変だった。
この週の金曜日、江木さんが東大の出身研究室(萩谷研)を訪問するというのでくっついて行った。 萩谷研では、Egisonの意味論をどう定義するかという話をしていた(僕は議論する様子を眺める係をしていた)。 この議論は後々論文になり、APLAS 2018に採択されている。
インターン3週目
2週目に設計した型システムを型検査器として実装した。 基本的にはHM型の制約解消アルゴリズムで実装したが、 型付けできない式を受理するためにワイルドカード型を入れたりした(Egisonはもともと型なしの言語なので、型付けできないが動く式が基本ライブラリ中に存在する)。 当時は知らなかったのだが、あとで確認してみると漸進的型付けの型検査と同じような実装になっていた。
インターン4週目
引き続き型検査器を実装した。
matcherを正しく型付けできたときがとても嬉しかったのを覚えている。

↑インターン中の食事の一例
インターン5週目
成果発表のためのスライド制作&発表練習をした。 スライドが全直しになったりしていい経験になった。 この経験が後々、未踏の二次審査で役に立ったような気がする。 最終発表の後で江木さんと二人でもんじゃ焼きを食べにいった。
感想
インターンを通して基本的に江木さんと二人だけで仕事をしていたが、江木さんがとても良い方だったのであまり苦ではなかった。 また週に一度kotapikuさんや梅崎さんがアルバイトに来て、数学の話をしたりするのが楽しかった。 食堂も大変美味しいのでついつい食べすぎてしまい、かなり太った。
ISUCON8予選に参加した
ISUCON8の予選にokeigoさん、mayokoさんとチーム「しょラーさんのおかげ」として参加していた。 最終的な得点は8000点くらいで予選落ちだった。悔しい。
チームメイトの参加記
予選まで
とか言っていたらISUCON出てみたいけどその分野について全く知らない
— a_kawashiro (@a_kawashiro) July 15, 2018
としょらーさんの穴を埋める形で誘ってもらい、参加することになった。ご検討ください https://t.co/fOPEOwDecN
— しょラー (@shora_kujira16) July 15, 2018
ISUCONの参加が決定してからは手元でISUCON7の予選、ISUCON6の予選を立てて練習していた。 N+1クエリ問題について初めて知った。 あとsystemd、MySQL、nginx、pythonのプロファイラの設定も初めてでいろいろ勉強になった。
予選の一週間前にokeigoさんがISHOCON2をセットアップしてくれて、そのサーバを使って3人で練習した。 3人とも離れたところに住んでいるので、Discordで音声通話、Slackでチャット、GitHubでコードを共有することになった。 言語は3人とも読めるPythonを使うことにした。
予選当日
朝
6時ぐらいに目が覚めた。いつもより6時間くらい早起き。
10時〜
予選スタート。 設定ファイルやpythonのアプリの実装をデプロイするスクリプトを書いた。 h2oをnginxに切り替えるのはokeigoさんがやってくれた。 この間にmayokoさんがアプリを読んでいた。
11時〜
とりあえずベンチマークを取った。
/favicon.icoが異常に重かったのだが、okeigoさんが設定のtypoを見つけて直したら解消した。
13時〜
僕はapp.pyの中でsheetをランダムに並び替えているところを小手先の小技で高速化しようとしていた。
が、あまり早くならなかった。
mayokoさんとokeigoさんがapp.pyのget_eventの改善をやっていた。
14時〜
mayokoさんの実装が終わった。 マージしてベンチを取ったら5000点ぐらい出て、学生3位になったので正直勝ったと思った。
15時〜
okeigoさんがredisを使ってキャッシュを実装していた。 venv環境にどうやってredisをインストールするのかがわからずに悪戦苦闘した。 結局バイナリをコピーして対応したらしい。SUGOI
16時〜
キャッシュの実装が動いたので、そろそろ3台構成にしましょうか、という話になった。 が、ポートの開放とかでいろいろ詰まった。 僕はあんまり何もできなかった。
17時〜
17:30ぐらいに3台構成が動いた。 あとは何度がベンチマークをとって終了。 最終的には7900点ぐらいでたはず。
18時〜
お祈りした。
— a_kawashiro (@a_kawashiro) September 16, 2018
19時ごろ
結果が出た。予選を通過することはできなかった。
燃え尽きたので起き上がれない
— a_kawashiro (@a_kawashiro) September 16, 2018
反省
- okeigoさんの負担が重すぎた。もうちょっとサーバの設定とか練習しとけばよかった。
- 役割分担がきちんと決まっていなかった。アプリ2人、インフラ1人というのがバランスが良さそうだった。
- 複数台構成におけるサーバ間の通信についてわかっていなかった。ISUCONのような特殊な環境ではファイヤーウォールを切って、全サービスが
0.0.0.0:portをリッスンしてしまえば良いと思った。 - サービスとして登録するpythonスクリプトに新しくライブラリ(
redis)を追加する処理についてわかっていなかった。 - プロファイルをちゃんと見ていなかった。ログの可視化スクリプトを作成しておくべきだった。
まとめ
チカラが足りなかった。悔しい。